Model Configuration
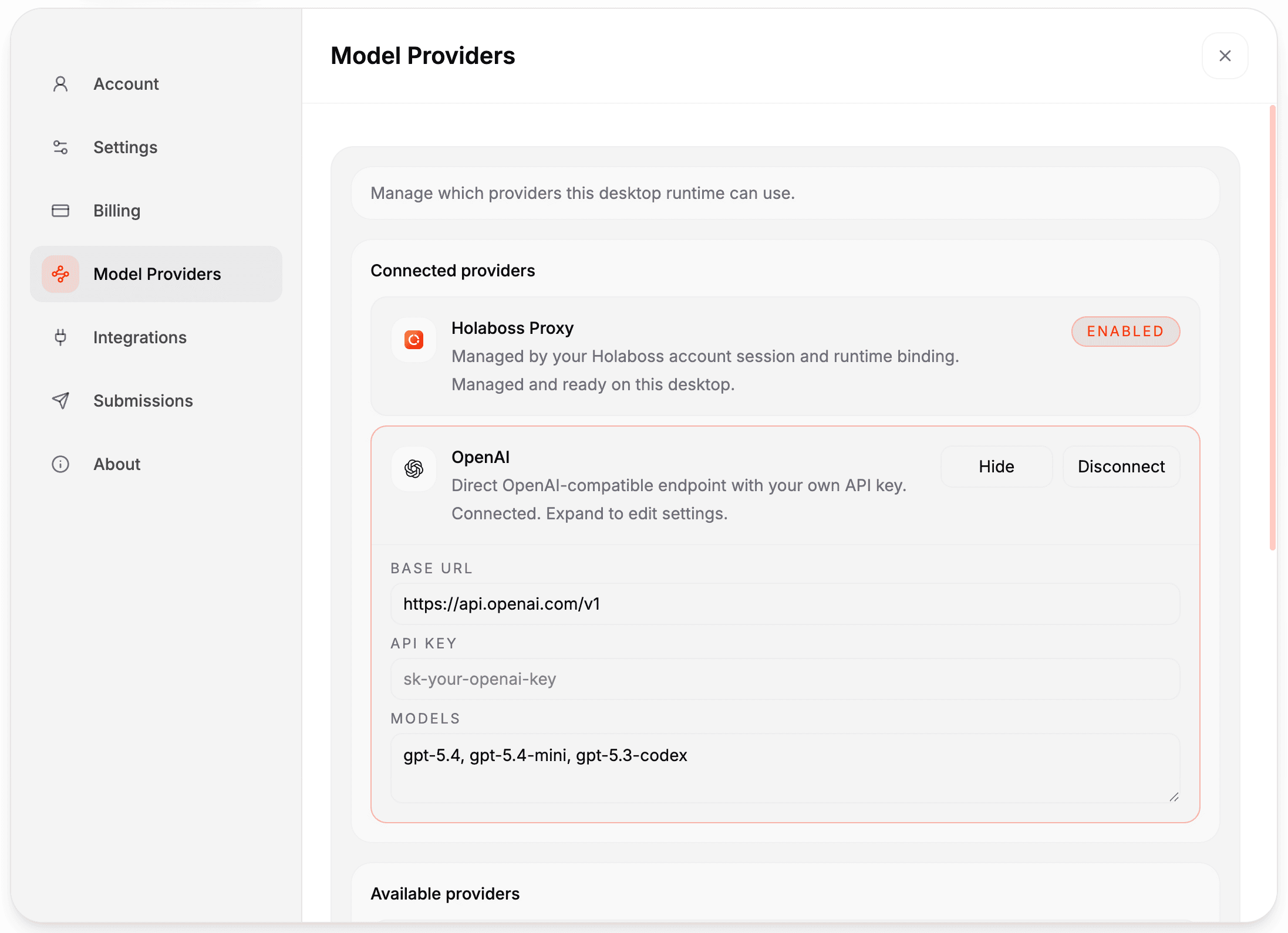
Holaboss ships with a default model setup. In most cases, you do not need to edit runtime-config.json by hand, because the desktop app already exposes the main configuration surfaces for provider connection, managed model catalogs, background tasks, recall embeddings, and image generation.
This page is the configuration reference for operators and builders. For the Electron IPC path, runtime model-catalog refresh flow, queued thinking_value handoff, and other execution internals, continue into Desktop Internals and Runtime APIs.
The baseline defaults are:
- default model:
openai/gpt-5.4 - built-in fallback provider id when no configured default provider applies:
openai
Supported provider styles
The OSS runtime supports the following provider kinds:
| Provider kind | Best fit | Notes |
|---|---|---|
holaboss_proxy | Holaboss-managed setups | Uses the Holaboss runtime binding and managed model catalog instead of a local seed list. |
openai_compatible | Self-hosted or compatible APIs | Best when you already have an OpenAI-style endpoint. Also covers OpenAI, Gemini, Ollama, and MiniMax. |
anthropic_native | Anthropic accounts and native workflows | Good when you want the provider's own integration path. |
openrouter | Model experimentation and broad access | Useful when you want to swap models without changing the rest of the setup. |
The desktop settings UI (Settings -> Model Providers) lets you connect Holaboss Proxy, OpenAI, Anthropic, OpenRouter, Gemini, Ollama, or MiniMax without editing files manually.
In-app setup
Holaboss already provides model configuration in the desktop app:
- open
Settings -> Model Providers - connect a provider such as Holaboss Proxy, OpenAI, Anthropic, OpenRouter, Gemini, Ollama, or MiniMax
- enter the API key and use the built-in provider defaults or edit the model list for that provider
- use the
Background taskspanel to choose one connected provider and model for recall selection, finalization, and evolve tasks - use the
Recall embeddingspanel to leave vector-assisted recall onAutomaticor choose an explicit embedding-capable provider and model - use the
Image generationpanel to choose an image-capable provider and model for runtime image generation - changes autosave to
runtime-config.json, and the chat model picker uses the configured provider models
When the first direct provider is connected, the desktop seeds background tasks to that provider and its built-in default background model. Holaboss-managed sessions can also inject managed background and embedding defaults through the runtime binding. For ollama_direct, the provider can be selected, but you must choose a model explicitly before background LLM tasks are enabled.
Catalog-driven chat models
The current desktop no longer treats chat models as only freeform strings.
- Direct providers use the shipped fallback catalog in
desktop/shared/model-catalog.ts. - Signed-in Holaboss-managed sessions can also fetch a managed runtime model catalog from the control plane.
- The desktop merges that managed catalog with the locally persisted
runtime-config.jsonand exposes the result asproviderModelGroupsin the runtime-config snapshot. - Managed defaults for background tasks, embeddings, and image generation are also carried with that snapshot as
defaultBackgroundModel,defaultEmbeddingModel, anddefaultImageModel.
In practice, that means the model picker and settings UI are both catalog-aware:
Settings -> Model Providersuses the catalog to seed provider defaults and suggestions.- The chat composer uses the resolved provider groups to show only the models that are actually available for the current runtime.
- Deprecated or unsupported model ids are filtered before they reach the renderer.
Reasoning effort in chat
Reasoning effort is selected in the chat composer, not in runtime-config.json.
The current flow is:
- select a chat model in the composer
- if that model advertises
reasoning: trueand has non-emptythinkingValues, the composer shows aThinkingselector - the desktop remembers the last selected value per resolved model locally
- when the message is queued, the desktop sends both
modelandthinking_valueto/api/v1/agent-sessions/queue
That thinking_value is run-scoped metadata. It does not become a new global default model setting.
Current shipped reasoning-value sets
The shipped fallback catalog currently exposes these reasoning controls:
| Provider / model | Reasoning values |
|---|---|
openai_direct/gpt-5.4 | none, low, medium, high, xhigh |
openai_direct/gpt-5.3-codex | low, medium, high, xhigh |
anthropic_direct/claude-sonnet-4-6 | low, medium, high |
anthropic_direct/claude-opus-4-6 | low, medium, high, max |
anthropic_direct/claude-haiku-4-5 | 1024, 2048, 8192, 16384 |
openrouter_direct/* shipped chat models | minimal, low, medium, high |
gemini_direct/gemini-2.5-pro | -1, 128, 2048, 8192, 32768 |
gemini_direct/gemini-2.5-flash | 0, -1, 128, 2048, 8192, 24576 |
ollama_direct/* shipped models | no reasoning selector |
minimax_direct/* shipped models | no reasoning selector |
For Holaboss Proxy, the managed catalog can provide explicit reasoning metadata. If it does not, the desktop falls back to provider-mapped metadata for known OpenAI, Anthropic, Gemini, and shipped OpenRouter models.
Customization mode
You can configure the runtime in either of these modes:
- legacy or proxy shorthand
- set
model_proxy_base_url,auth_token, anddefault_model
- set
- structured provider catalog
- define
providersandmodels, then setruntime.default_providerandruntime.default_model
- define
Runtime URL behavior stays consistent across both modes:
- if
model_proxy_base_urlis a proxy root, runtime appends provider routes such as/openai/v1or/anthropic/v1 - direct mode is enabled when you provide a provider endpoint
- OpenAI-compatible direct providers typically use a
/v1endpoint, for examplehttps://api.openai.com/v1 - Anthropic native direct providers should use the root host, for example
https://api.anthropic.com - known provider hosts normalize as needed, including Gemini host roots to
/v1beta/openai
Where the runtime reads model config
The runtime resolves model settings from:
runtime-config.json- environment variables
- built-in defaults
By default, runtime-config.json lives at:
${HB_SANDBOX_ROOT}/state/runtime-config.json
You can override that path with:
HOLABOSS_RUNTIME_CONFIG_PATH
Important settings
model_proxy_base_url- legacy or proxy base URL root
auth_token- proxy token sent as
X-API-Key
- proxy token sent as
providers.<id>.base_url- direct provider endpoint
providers.<id>.api_key- direct provider credential
runtime.background_tasks.provider- provider for recall selection, finalization, and evolve tasks
runtime.background_tasks.model- model id used for that background provider
runtime.recall_embeddings.provider- optional embedding-capable provider used for vector-assisted recall candidate narrowing
runtime.recall_embeddings.model- optional embedding model id used for recall embeddings
runtime.image_generation.provider- provider used for runtime image generation
runtime.image_generation.model- image model id used for runtime image generation
runtime.default_provider- configured default provider for unprefixed model ids
runtime.default_model- default model selection
HOLABOSS_DEFAULT_MODEL- environment override for the default model
There is no runtime.thinking_value field. Reasoning effort is chosen per run in the chat composer and queued with the session input.
Background task provider defaults
The current built-in background task defaults are:
holaboss_model_proxy:gpt-5.4openai_direct:gpt-5.4anthropic_direct:claude-sonnet-4-6openrouter_direct:openai/gpt-5.4gemini_direct:gemini-2.5-flashminimax_direct:MiniMax-M2.7ollama_direct: no default; choose a model explicitly
Recall embedding defaults
When Recall embeddings is left on Automatic, runtime chooses the first configured provider that has a built-in embedding default. If you configure it explicitly, the current built-in embedding defaults are:
holaboss_model_proxy:text-embedding-3-smallopenai_direct:text-embedding-3-smallopenrouter_direct:openai/text-embedding-3-small
Gemini, Ollama, and MiniMax currently have no built-in embedding default, so vector-assisted recall stays off until a compatible embedding model is configured where supported.
Image generation provider defaults
The desktop currently exposes image generation only for the providers that can resolve an image-capable model in the shipped UI:
holaboss_model_proxy: managed catalog / runtime-binding defaults when availableopenai_direct:gpt-image-1.5openrouter_direct:google/gemini-3.1-flash-image-previewgemini_direct:gemini-3.1-flash-image-preview
The current shipped desktop does not provide built-in image-generation defaults for:
anthropic_directollama_directminimax_direct
Model string format
Use provider-prefixed model ids when you want to be explicit:
openai/gpt-5.4anthropic/claude-sonnet-4-6openrouter/deepseek/deepseek-chat-v3-0324
The runtime also treats unprefixed claude... model ids as Anthropic models. If a model id is unprefixed and does not start with claude, the runtime first tries the configured default provider. If no configured default provider applies, it falls back to openai/<model>.
runtime-config.json universal provider example
{
"runtime": {
"default_provider": "openai_direct",
"default_model": "openai/gpt-5.4",
"background_tasks": {
"provider": "openai_direct",
"model": "gpt-5.4"
},
"image_generation": {
"provider": "openai_direct",
"model": "gpt-image-1.5"
},
"recall_embeddings": {
"provider": "openai_direct",
"model": "text-embedding-3-small"
}
},
"providers": {
"openai_direct": {
"kind": "openai_compatible",
"base_url": "https://api.openai.com/v1",
"api_key": "sk-your-openai-key"
},
"anthropic_direct": {
"kind": "anthropic_native",
"base_url": "https://api.anthropic.com",
"api_key": "sk-ant-your-anthropic-key"
},
"openrouter_direct": {
"kind": "openrouter",
"base_url": "https://openrouter.ai/api/v1",
"api_key": "sk-or-your-openrouter-key"
},
"gemini_direct": {
"kind": "openai_compatible",
"base_url": "https://generativelanguage.googleapis.com/v1beta/openai",
"api_key": "AIza-your-gemini-api-key"
},
"ollama_direct": {
"kind": "openai_compatible",
"base_url": "http://localhost:11434/v1",
"api_key": "ollama"
}
},
"models": {
"openai_direct/gpt-5.4": {
"provider": "openai_direct",
"model": "gpt-5.4"
},
"openai_direct/gpt-5.3-codex": {
"provider": "openai_direct",
"model": "gpt-5.3-codex"
},
"anthropic_direct/claude-sonnet-4-6": {
"provider": "anthropic_direct",
"model": "claude-sonnet-4-6"
},
"openrouter_direct/openai/gpt-5.4": {
"provider": "openrouter_direct",
"model": "openai/gpt-5.4"
},
"gemini_direct/gemini-2.5-flash": {
"provider": "gemini_direct",
"model": "gemini-2.5-flash"
},
"ollama_direct/llama3.1:8b": {
"provider": "ollama_direct",
"model": "llama3.1:8b"
}
}
}Provider kind values supported by the runtime resolver:
holaboss_proxyopenai_compatibleanthropic_nativeopenrouter
Verify Ollama through the desktop UI
This is the simplest end-to-end check for the local ollama_direct path:
- Install and start Ollama on your machine.
- Pull a small local model:
ollama pull llama3.1:8b- Launch the desktop app.
- Open
Settings -> Model Providers. - Connect
Ollamawith:- base URL:
http://localhost:11434/v1 - API key:
ollama - models:
llama3.1:8b
- base URL:
- Open a workspace chat and select
ollama_direct/llama3.1:8b. - Send this prompt:
Reply with exactly: OKExpected result:
- the run starts with provider
ollama_direct - the model resolves to
llama3.1:8b - the assistant replies with
OK
If the model does not show up or the request fails, verify Ollama directly first:
curl http://localhost:11434/v1/chat/completions \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer ollama' \
-d '{"model":"llama3.1:8b","messages":[{"role":"user","content":"Reply with exactly: OK"}],"temperature":0}'Environment overrides
export HOLABOSS_MODEL_PROXY_BASE_URL="https://your-proxy.example/api/v1/model-proxy"
export HOLABOSS_SANDBOX_AUTH_TOKEN="your-proxy-token"
export HOLABOSS_DEFAULT_MODEL="anthropic/claude-sonnet-4-6"These environment variables override the file-based values above. sandbox_id is still the current field name in runtime-config.json.