Model Configuration
Holaboss ships with a default model setup. In most cases, you do not need to edit runtime-config.json by hand, because the desktop app already exposes the main configuration surfaces.
The baseline defaults are:
- default model:
openai/gpt-5.4 - built-in fallback provider id when no configured default provider applies:
openai
Supported provider styles
The OSS runtime supports the following provider kinds:
| Provider kind | Best fit | Notes |
|---|---|---|
holaboss_proxy | Holaboss-managed setups | Useful when the desktop should talk through the Holaboss proxy layer. |
openai_compatible | Self-hosted or compatible APIs | Best when you already have an OpenAI-style endpoint. Also covers Ollama. |
anthropic_native | Anthropic accounts and native workflows | Good when you want the provider's own integration path. |
openrouter | Model experimentation and broad access | Useful when you want to swap models without changing the rest of the setup. |
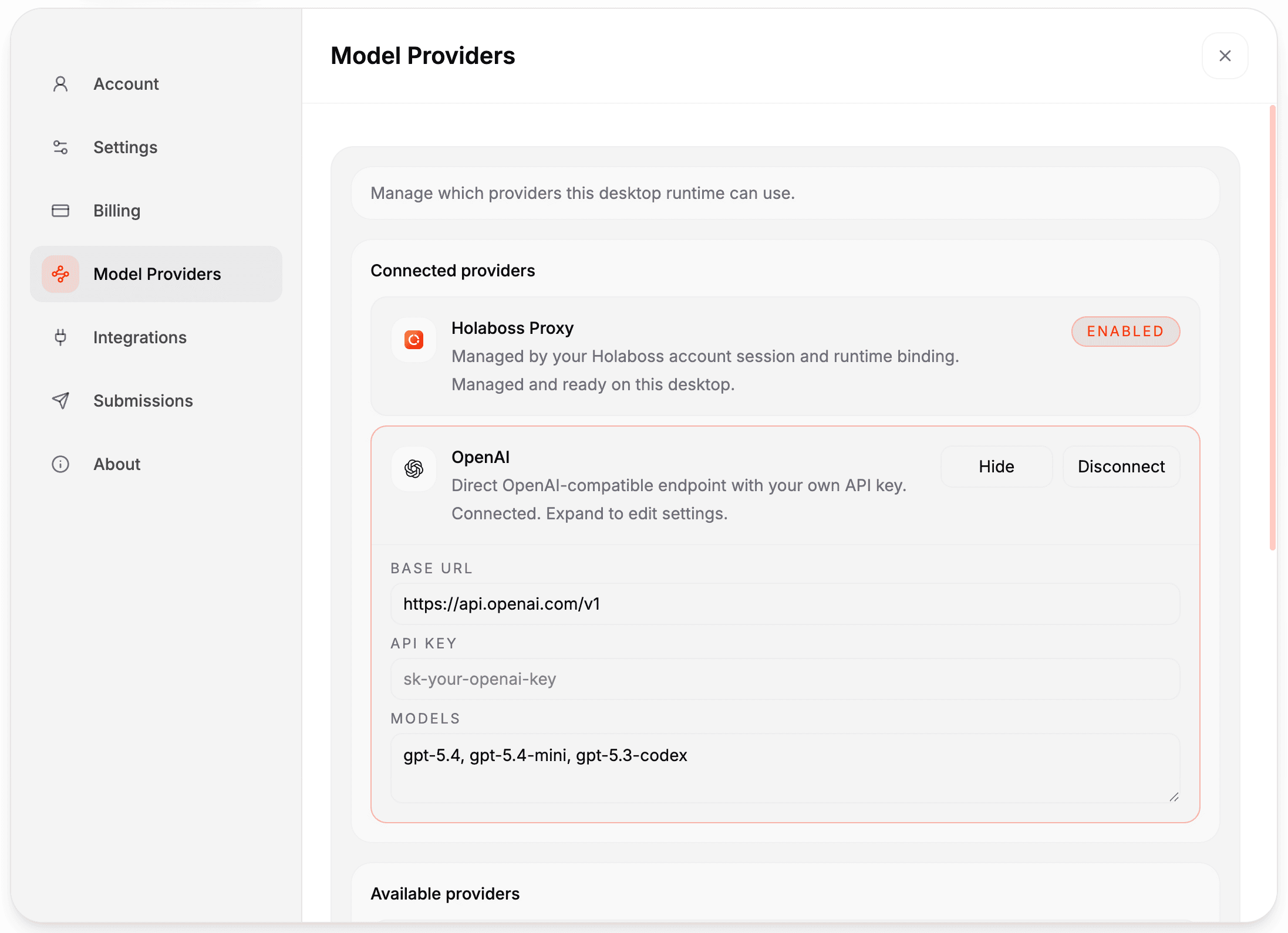
The desktop settings UI (Settings -> Model Providers) lets you connect OpenAI, Anthropic, OpenRouter, Gemini, or Ollama without editing files manually.
In-app setup
Holaboss already provides model configuration in the desktop app:
- open
Settings -> Model Providers - connect a provider such as OpenAI, Anthropic, OpenRouter, Gemini, or Ollama
- enter the API key and use the built-in provider defaults or edit the model list for that provider
- use the
Background taskspanel to choose one connected provider and model for recall selection, finalization, and evolve tasks - use the
Recall embeddingspanel to leave vector-assisted recall onAutomaticor choose an explicit embedding-capable provider and model - changes autosave to
runtime-config.json, and the chat model picker uses the configured provider models
When the first provider is connected, the desktop seeds background tasks to that provider and its built-in default background model. For ollama_direct, the provider can be selected, but you must choose a model explicitly before background LLM tasks are enabled.
Customization mode
You can configure the runtime in either of these modes:
- legacy or proxy shorthand
- set
model_proxy_base_url,auth_token, anddefault_model
- set
- structured provider catalog
- define
providersandmodels, then setruntime.default_providerandruntime.default_model
- define
Runtime URL behavior stays consistent across both modes:
- if
model_proxy_base_urlis a proxy root, runtime appends provider routes such as/openai/v1or/anthropic/v1 - direct mode is enabled when you provide a provider endpoint
- OpenAI-compatible direct providers typically use a
/v1endpoint, for examplehttps://api.openai.com/v1 - Anthropic native direct providers should use the root host, for example
https://api.anthropic.com - known provider hosts normalize as needed, including Gemini host roots to
/v1beta/openai
Where the runtime reads model config
The runtime resolves model settings from:
runtime-config.json- environment variables
- built-in defaults
By default, runtime-config.json lives at:
${HB_SANDBOX_ROOT}/state/runtime-config.json
You can override that path with:
HOLABOSS_RUNTIME_CONFIG_PATH
Important settings
model_proxy_base_url- legacy or proxy base URL root
auth_token- proxy token sent as
X-API-Key
- proxy token sent as
providers.<id>.base_url- direct provider endpoint
providers.<id>.api_key- direct provider credential
runtime.background_tasks.provider- provider for recall selection, finalization, and evolve tasks
runtime.background_tasks.model- model id used for that background provider
runtime.recall_embeddings.provider- optional embedding-capable provider used for vector-assisted recall candidate narrowing
runtime.recall_embeddings.model- optional embedding model id used for recall embeddings
runtime.default_provider- configured default provider for unprefixed model ids
runtime.default_model- default model selection
HOLABOSS_DEFAULT_MODEL- environment override for the default model
Background task provider defaults
When you choose a provider in the desktop Background tasks panel, the app seeds the model field with these defaults:
holaboss_model_proxy:gpt-5.4-miniopenai_direct:gpt-5.4-minianthropic_direct:claude-sonnet-4-6openrouter_direct:openai/gpt-5.4-minigemini_direct:gemini-2.5-flashminimax_direct:MiniMax-M2.7ollama_direct: no default; choose a model explicitly
Recall embedding defaults
When Recall embeddings is left on Automatic, runtime chooses the first configured provider that has a built-in embedding default. If you configure it explicitly, the current built-in embedding defaults are:
openai_direct:text-embedding-3-smallopenrouter_direct:openai/text-embedding-3-small
Other providers currently need an explicit compatible embedding model selection before vector-assisted recall is enabled.
Model string format
Use provider-prefixed model ids when you want to be explicit:
openai/gpt-5.4anthropic/claude-sonnet-4-20250514openrouter/deepseek/deepseek-chat-v3-0324
The runtime also treats unprefixed claude... model ids as Anthropic models. If a model id is unprefixed and does not start with claude, the runtime first tries the configured default provider. If no configured default provider applies, it falls back to openai/<model>.
runtime-config.json universal provider example
{
"runtime": {
"default_provider": "openai_direct",
"default_model": "openai/gpt-5.4",
"background_tasks": {
"provider": "openai_direct",
"model": "gpt-5.4-mini"
},
"recall_embeddings": {
"provider": "openai_direct",
"model": "text-embedding-3-small"
}
},
"providers": {
"openai_direct": {
"kind": "openai_compatible",
"base_url": "https://api.openai.com/v1",
"api_key": "sk-your-openai-key"
},
"anthropic_direct": {
"kind": "anthropic_native",
"base_url": "https://api.anthropic.com",
"api_key": "sk-ant-your-anthropic-key"
},
"openrouter_direct": {
"kind": "openrouter",
"base_url": "https://openrouter.ai/api/v1",
"api_key": "sk-or-your-openrouter-key"
},
"ollama_direct": {
"kind": "openai_compatible",
"base_url": "http://localhost:11434/v1",
"api_key": "ollama"
}
},
"models": {
"openai_direct/gpt-5.4": {
"provider": "openai_direct",
"model": "gpt-5.4"
},
"openai_direct/gpt-5.4-mini": {
"provider": "openai_direct",
"model": "gpt-5.4-mini"
},
"anthropic_direct/claude-sonnet-4-6": {
"provider": "anthropic_direct",
"model": "claude-sonnet-4-6"
},
"openrouter_direct/openai/gpt-5.4": {
"provider": "openrouter_direct",
"model": "openai/gpt-5.4"
},
"ollama_direct/qwen2.5:0.5b": {
"provider": "ollama_direct",
"model": "qwen2.5:0.5b"
}
}
}Provider kind values supported by the runtime resolver:
holaboss_proxyopenai_compatibleanthropic_nativeopenrouter
Verify Ollama through the desktop UI
This is the simplest end-to-end check for the local ollama_direct path:
- Install and start Ollama on your machine.
- Pull a small local model:
ollama pull qwen2.5:0.5b- Launch the desktop app.
- Open
Settings -> Model Providers. - Connect
Ollamawith:- base URL:
http://localhost:11434/v1 - API key:
ollama - models:
qwen2.5:0.5b
- base URL:
- Open a workspace chat and select
ollama_direct/qwen2.5:0.5b. - Send this prompt:
Reply with exactly: OKExpected result:
- the run starts with provider
ollama_direct - the model resolves to
qwen2.5:0.5b - the assistant replies with
OK
If the model does not show up or the request fails, verify Ollama directly first:
curl http://localhost:11434/v1/chat/completions \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer ollama' \
-d '{"model":"qwen2.5:0.5b","messages":[{"role":"user","content":"Reply with exactly: OK"}],"temperature":0}'Environment overrides
export HOLABOSS_MODEL_PROXY_BASE_URL="https://your-proxy.example/api/v1/model-proxy"
export HOLABOSS_SANDBOX_AUTH_TOKEN="your-proxy-token"
export HOLABOSS_DEFAULT_MODEL="anthropic/claude-sonnet-4-20250514"These environment variables override the file-based values above. sandbox_id still needs to come from runtime-config.json.